Машинное обучение
Машинное обучение предоставляет компьютеру данные, а не явные инструкции. Используя эти данные, компьютер учится распознавать закономерности и может самостоятельно выполнять задачи.
Обучение с учителем
Обучение с учителем — это задача, в которой компьютер обучает функцию, которая сопоставляет входные данные с выходными на основе набора данных пар ввода-вывода.
В рамках контролируемого обучения существует множество задач, и одна из них — классификация. Это задача, в которой функция сопоставляет вход с дискретным выходом. Например, получив некоторую информацию о влажности и давлении воздуха за определённый день (входные данные), компьютер решает, будет ли в этот день дождь или нет (выходные данные). Компьютер делает это после обучения на наборе данных с несколькими днями, где влажность и давление воздуха уже сопоставлены с тем, шёл дождь или нет.
Эту задачу можно формализовать следующим образом. Мы наблюдаем природу, где функция f(влажность, давление) отображает входные данные в дискретное значение: дождь или отсутствие дождя. Эта функция скрыта от нас, и на неё, вероятно, влияют многие другие переменные, к которым у нас нет доступа. Наша цель — создать функцию h(влажность, давление), которая может аппроксимировать поведение функции f. Такую задачу можно визуализировать, отобразив дни по измерениям влажности и дождя (входные данные), раскрасив каждую точку данных синим цветом, если в тот день шёл дождь, и красным, если в тот день дождя не было (выходные данные). Белая точка данных имеет только входные данные, а компьютеру необходимо определить выходные данные.
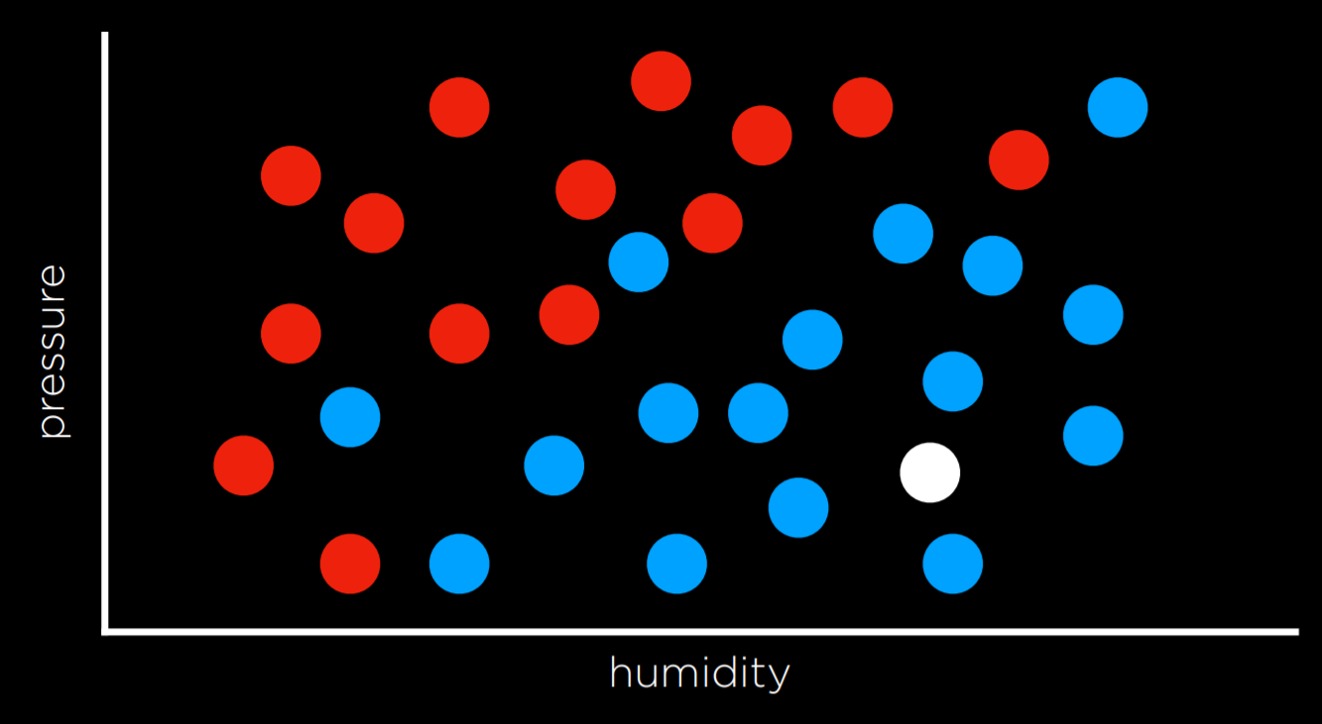
Классификация ближайших соседей
Одним из способов решения задачи, подобной описанной выше, является присвоение рассматриваемой переменной значения ближайшего наблюдения. Так, например, белая точка на графике выше будет окрашена в синий цвет, поскольку ближайшая наблюдаемая точка тоже синяя. Иногда это может сработать, но обратите внимание на график ниже.
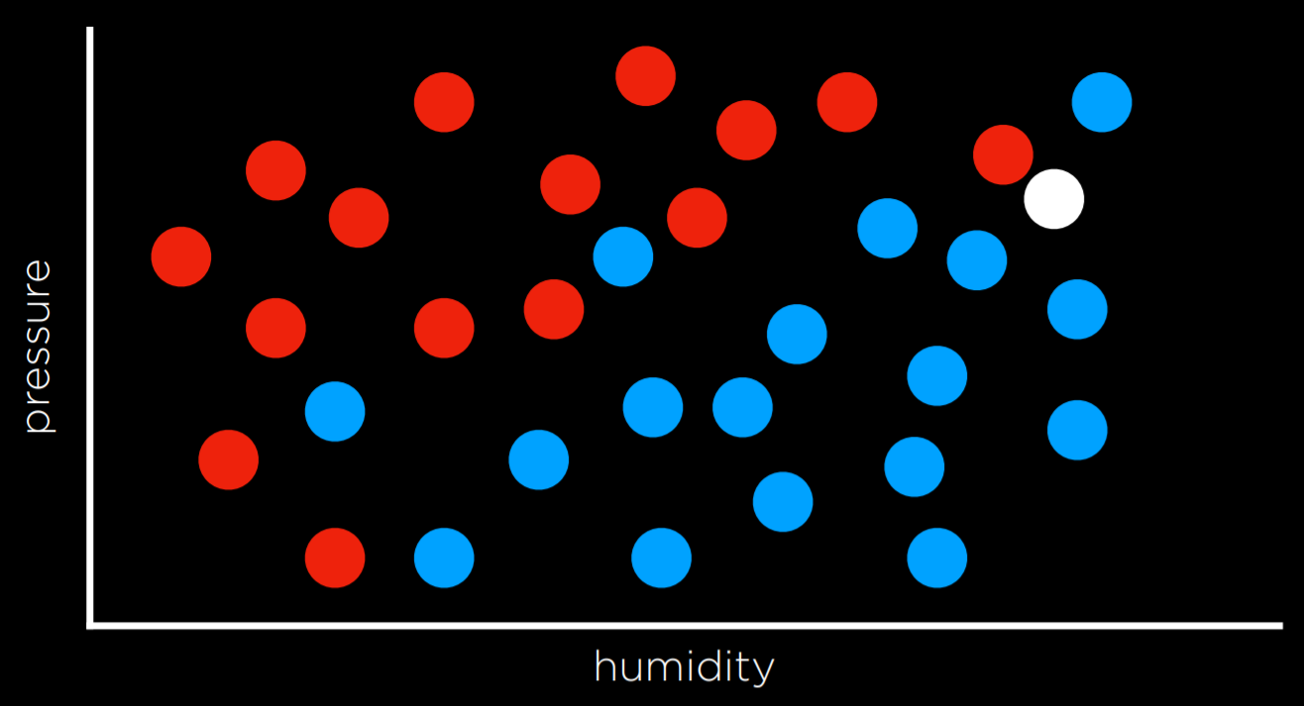
Следуя той же стратегии, белую точку следует покрасить в красный цвет, поскольку ближайшее к ней наблюдение тоже красного цвета. Однако, если посмотреть на картину в целом, похоже, что большинство других наблюдений вокруг него синие, что может дать нам интуитивное представление о том, что синий цвет в данном случае является лучшим прогнозом, хотя самое близкое наблюдение — красное.
Один из способов обойти ограничения классификации ближайших соседей — использовать классификацию k-ближайших соседей, при которой точка окрашивается на основе наиболее часто встречающегося цвета из k ближайших соседей. Программист должен решить, какое выбрать k. Например, при использовании классификации трёх ближайших соседей белая точка выше будет окрашена в синий цвет, что интуитивно кажется лучшим решением.
Недостаток классификации k-ближайших соседей заключается в том, что при использовании наивного подхода алгоритму придётся измерять расстояние каждой отдельной точки до рассматриваемой точки, что требует больших вычислительных затрат. Это можно ускорить, используя структуры данных, которые позволяют быстрее находить соседей, или отсекая ненужные наблюдения.
Перцептронное обучение
Другой способ решения проблемы классификации, в отличие от стратегии ближайшего соседа, заключается в рассмотрении данных в целом и попытке создать границу решения. В двумерных данных мы можем провести линию между двумя типами наблюдений. Каждая дополнительная точка данных будет классифицироваться в зависимости от стороны линии, на которой она нанесена.
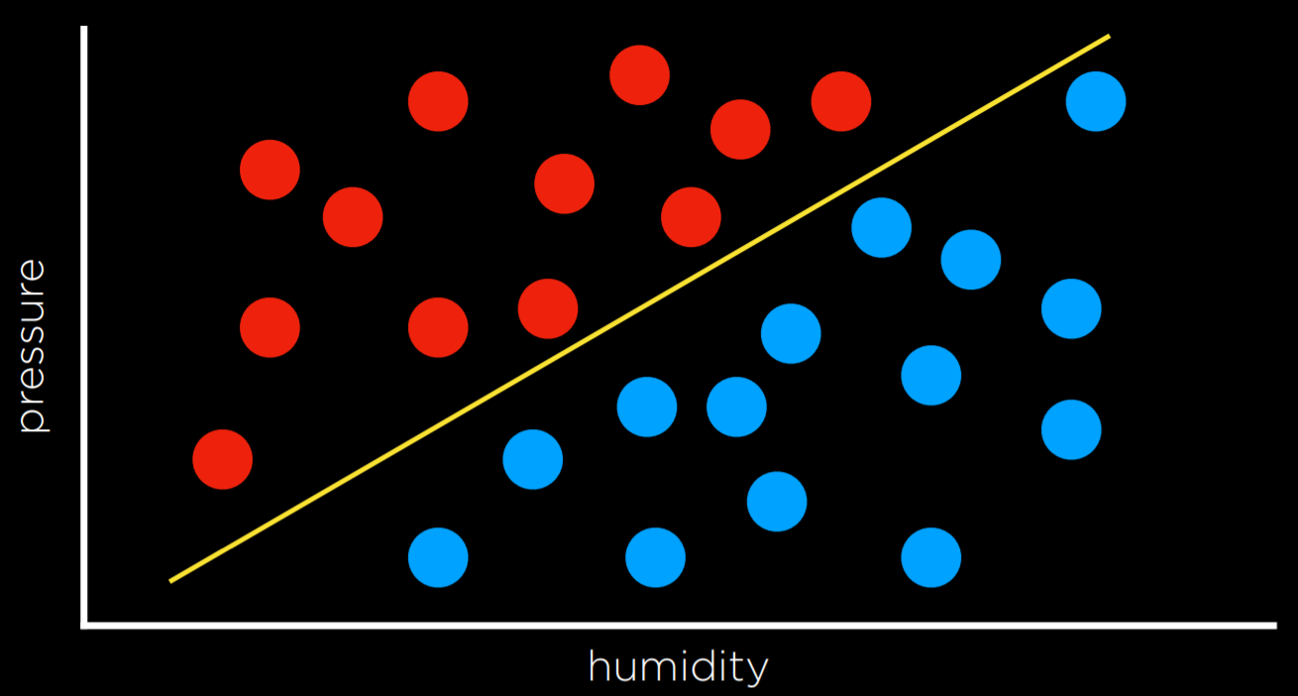
Недостаток этого подхода заключается в том, что данные беспорядочны, и редко удаётся провести линию и аккуратно разделить классы на два наблюдения без каких-либо ошибок. Часто мы идём на компромисс, проводя границу, которая чаще всего правильно разделяет наблюдения, но все же иногда неправильно их классифицирует.
В этом случае ввод:
- \(x_1\)= Humidity
- \(x_2\)= Pressure
- Дождь \(w_0+w_1x_1+w_2x_2\ge 0\)
- Нет дождя в противном случае
Часто выходная переменная кодируется как 1 и 0, где, если уравнение дает больше 0, выходной сигнал равен 1 (дождь), а в противном случае — 0 (нет дождя).
Веса и значения представлены векторами, которые представляют собой последовательности чисел (которые в Python можно хранить в списках или кортежах). Мы создаём весовой вектор w: \((w_0, w_1, w_2)\), и получение наилучшего весового вектора является целью алгоритма машинного обучения. Мы также создаём входной вектор x: \((1, x_1, x_2)\).
Мы берём скалярное произведение двух векторов. То есть мы умножаем каждое значение в одном векторе на соответствующее значение во втором векторе, получая выражение выше: w₀ + w₁x₁ + w₂x₂. Первое значение входного вектора равно 1, потому что при умножении на вектор веса w₀ мы хотим сохранить его постоянным.
Таким образом, мы можем представить нашу гипотезную функцию следующим образом: $$ h_w(x)=\left. \begin{array}{ll} 1 & if\; wx\ge0\\ 0 & otherwise \end{array} \right. $$
Поскольку целью алгоритма является поиск наилучшего вектора весов, когда алгоритм встречает новые данные, он обновляет текущие веса. Это делается с использованием правила обучения перцептрона:
$$ w_i=w_i+\alpha(y-h_w(x))x_i $$Важным выводом из этого правила является то, что для каждой точки данных мы корректируем веса, чтобы сделать нашу функцию более точной. Детали, которые с нашей точки зрения не так важны, заключаются в том, что каждый вес устанавливается равным самому себе плюс некоторое значение в скобках. Здесь y обозначает наблюдаемое значение, а функция гипотезы обозначает оценку. Если они идентичны, весь этот член равен нулю, и, следовательно, вес не изменяется. Если мы недооценили (вызов «Нет дождя, пока наблюдался дождь»), то значение в скобках будет равно 1, а вес увеличится на значение xᵢ, масштабированное с помощью коэффициента обучения α. Если мы переоценили (вызов Rain при отсутствии дождя), то значение в скобках будет -1, а вес уменьшится на значение x, масштабированное по α. Чем выше α, тем сильнее влияние каждого нового события на вес.
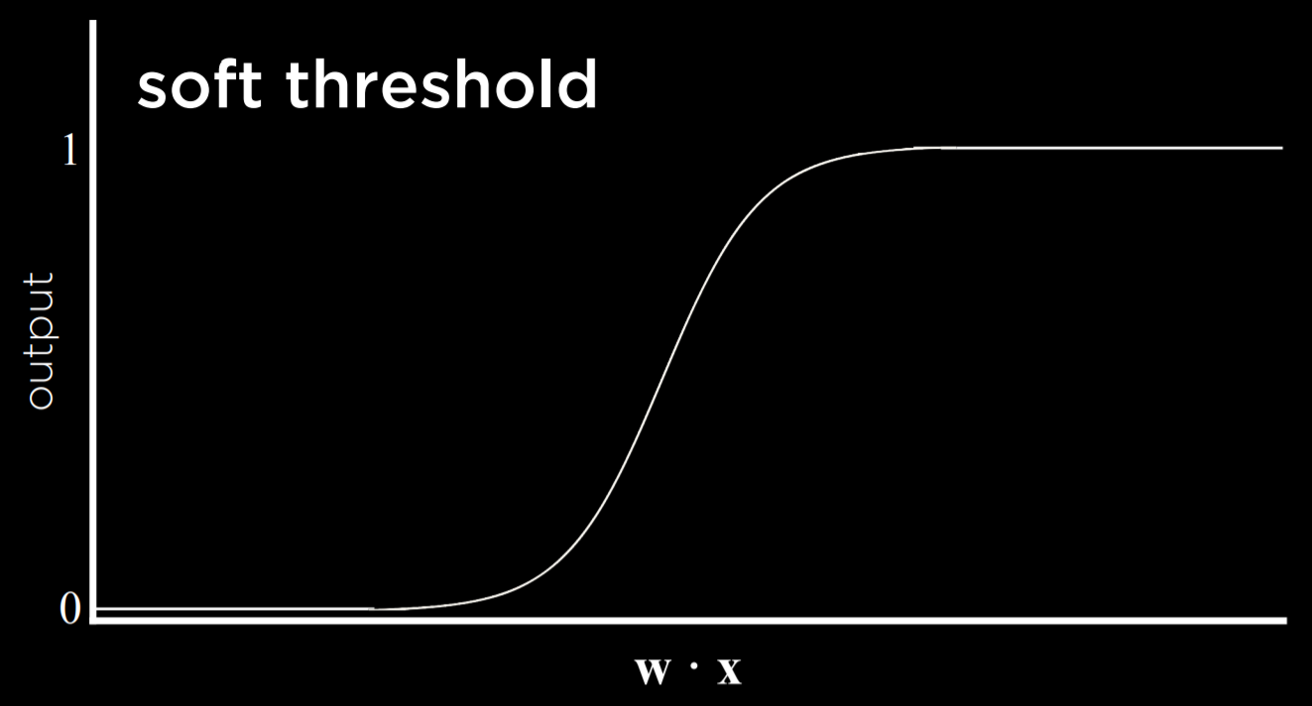
Результатом этого процесса является пороговая функция, которая переключается с 0 на 1, как только оценочное значение пересекает некоторый порог.
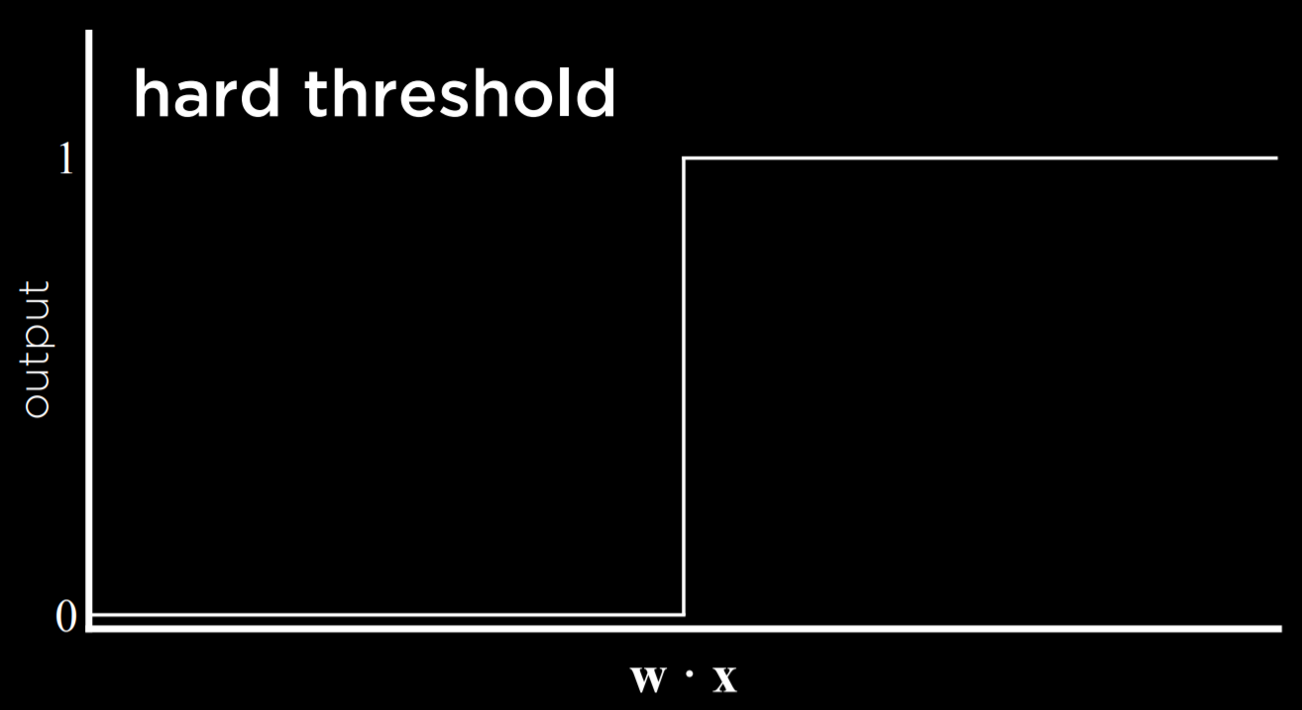
Проблема с этим типом функции заключается в том, что она не может выражать неопределенность, поскольку может быть равна только 0 или 1. Она использует жесткий порог. Чтобы обойти эту проблему, можно использовать логистическую функцию, которая использует мягкий порог. Логистическая функция может давать действительное число от 0 до 1, что будет выражать уверенность в оценке. Чем ближе значение к 1, тем больше вероятность дождя.
Машины опорных векторов
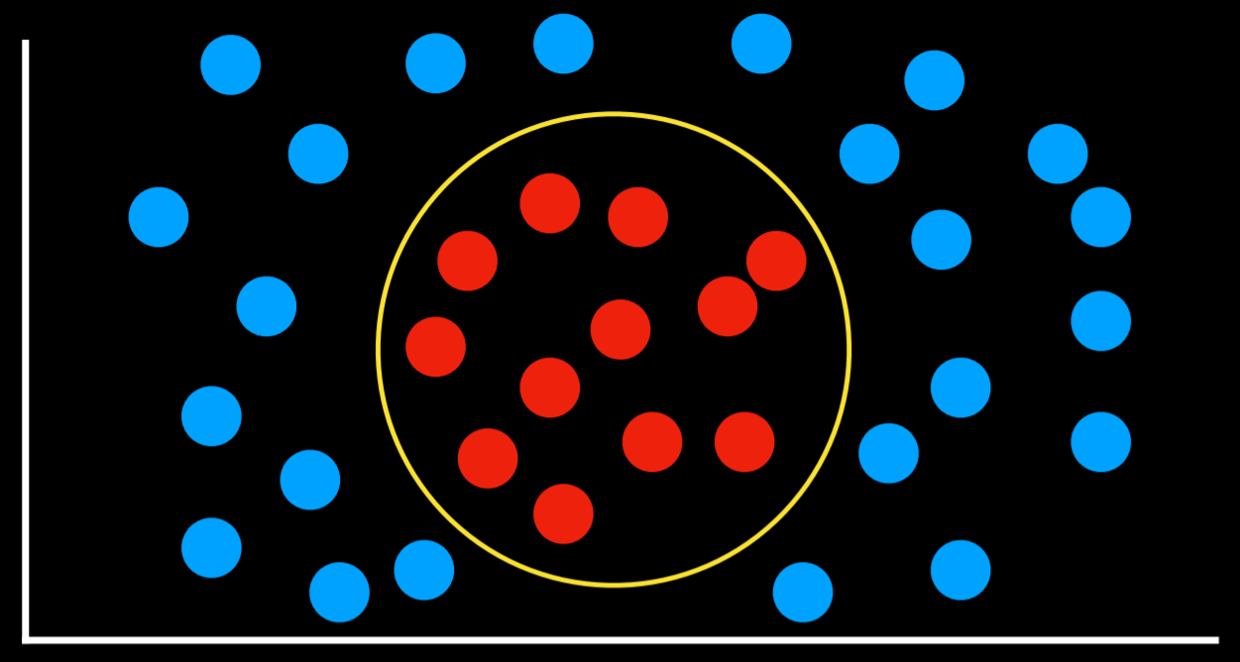
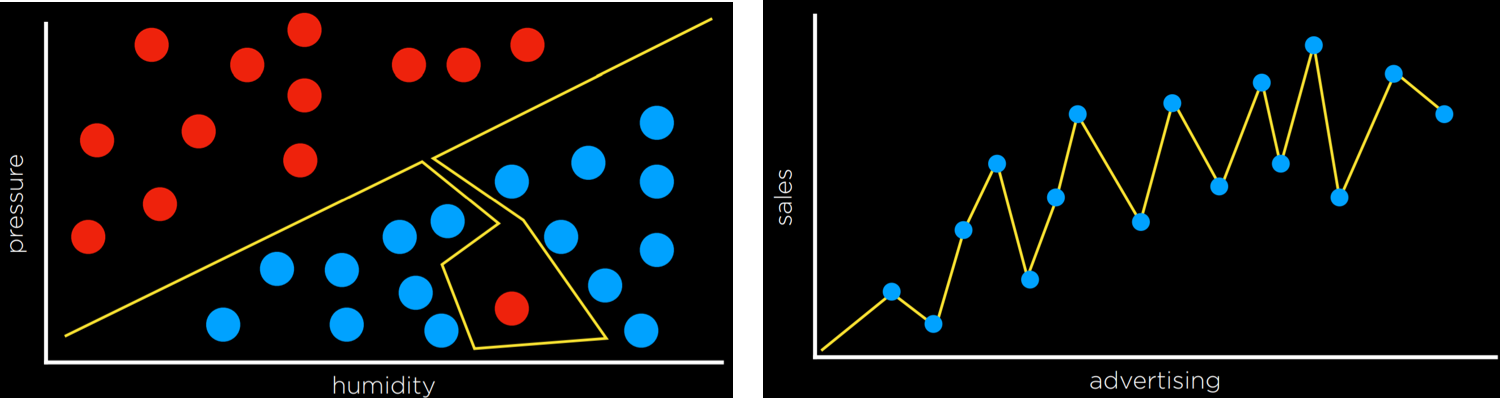
Помимо метода ближайшего соседа и линейной регрессии, еще одним подходом к классификации является машина опорных векторов. Этот подход использует дополнительный вектор (вектор поддержки) рядом с границей решения, чтобы принять лучшее решение при разделении данных. Рассмотрим пример ниже.

Все границы принятия решений работают таким образом, что разделяют данные без каких-либо ошибок. Однако одинаково ли они хороши? Две крайние левые границы решения очень близки к некоторым наблюдениям. Это означает, что новая точка данных, лишь незначительно отличающаяся от одной группы, может быть ошибочно отнесена к другой. Напротив, крайняя правая граница решений находится на наибольшем расстоянии от каждой из групп, что дает наибольшую свободу действий внутри нее. Этот тип границы, который находится как можно дальше от двух групп, которые он разделяет, называется разделителем максимального поля.
Еще одним преимуществом машин опорных векторов является то, что они могут представлять границы решений с более чем двумя измерениями, а также нелинейные границы решений, как показано ниже.
Подводя итог, можно сказать, что существует множество способов решения задач классификации, и нет такого, который всегда лучше других. Каждый из них имеет свои недостатки и может оказаться более полезным, чем другие, в конкретных ситуациях.
Регрессия
Регрессия — это задача обучения с учителем функции, которая сопоставляет входную точку с непрерывным значением, некоторым действительным числом. Это отличается от классификации тем, что задачи классификации отображают входные данные в дискретные значения (дождь или отсутствие дождя).
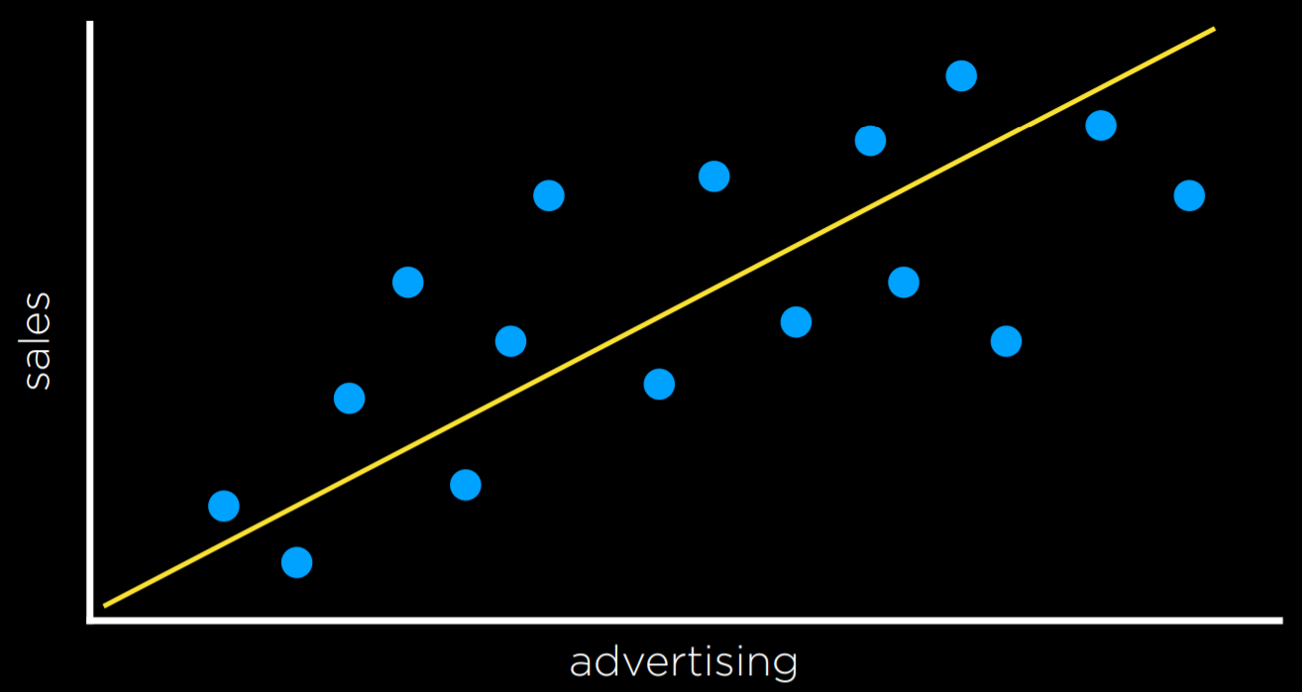
Например, компания может использовать регрессию, чтобы ответить на вопрос, как деньги, потраченные на рекламу, предсказывают деньги, полученные от продаж. В этом случае наблюдаемая функция f(реклама) представляет собой наблюдаемый доход после некоторой суммы денег, потраченных на рекламу (обратите внимание, что функция может принимать более одной входной переменной). Это данные, с которых мы начинаем. Используя эти данные, мы хотим придумать гипотезу функции h (реклама), которая попытается аппроксимировать поведение функции f. h сгенерирует линию, целью которой является не разделение типов наблюдений, а предсказание на основе входных данных того, каким будет значение выходных данных.
Функция потерь
Функции потерь — это способ количественной оценки числа неправильных предсказаний. Чем менее точный прогноз, тем больше потери.
Для задач классификации мы можем использовать функцию потерь 0-1.
L(действительное, предсказанное)- 0 если действительное = предсказанное
- 1 в других случаях
Другими словами, эта функция возвращает единицу, когда прогноз неверен, и не получает значения, когда он верен (т. е. когда наблюдаемые и прогнозируемые значения совпадают).
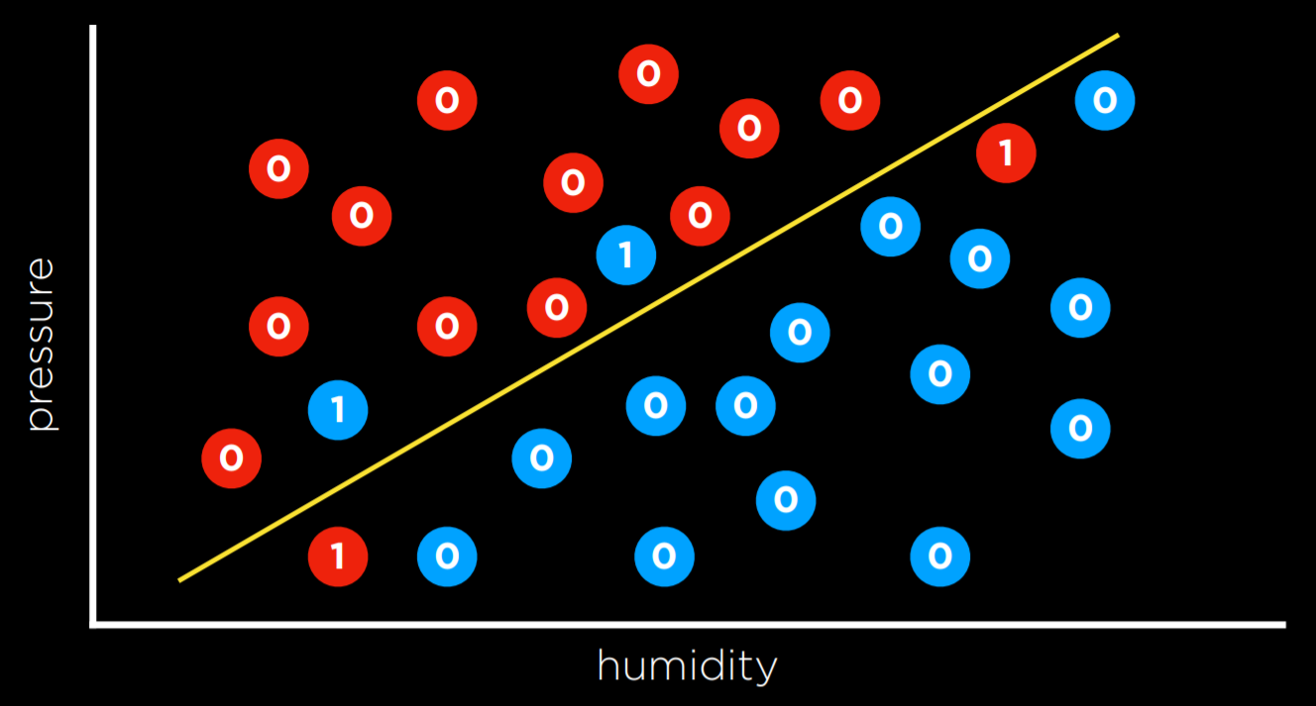
В приведенном выше примере дни, которые оцениваются в 0, — это те дни, когда мы правильно спрогнозировали погоду (дождливые дни находятся под линией, а не дождливые дни — над линией). Однако дни, когда дождь не шел ниже линии, и дни, когда дождь шел выше нее, — это те дни, которые мы не смогли предсказать. Мы даем каждому значение 1 и суммируем их, чтобы получить эмпирическую оценку того, насколько велики потери для границы принятия решений.
Функции потерь L₁ и L₂ можно использовать при прогнозировании непрерывного значения. В этом случае нас интересует количественная оценка для каждого прогноза того, насколько оно отличается от наблюдаемого значения. Мы делаем это, беря либо абсолютное значение, либо квадрат значения наблюдаемого значения минус прогнозируемое значение (т. е. насколько далеко прогноз был от наблюдаемого значения).
- L1:L(действительное, предсказанное) = |действительное-предсказанное|
- L2:L(действительное, предсказанное) = (действительное-предсказанное)2
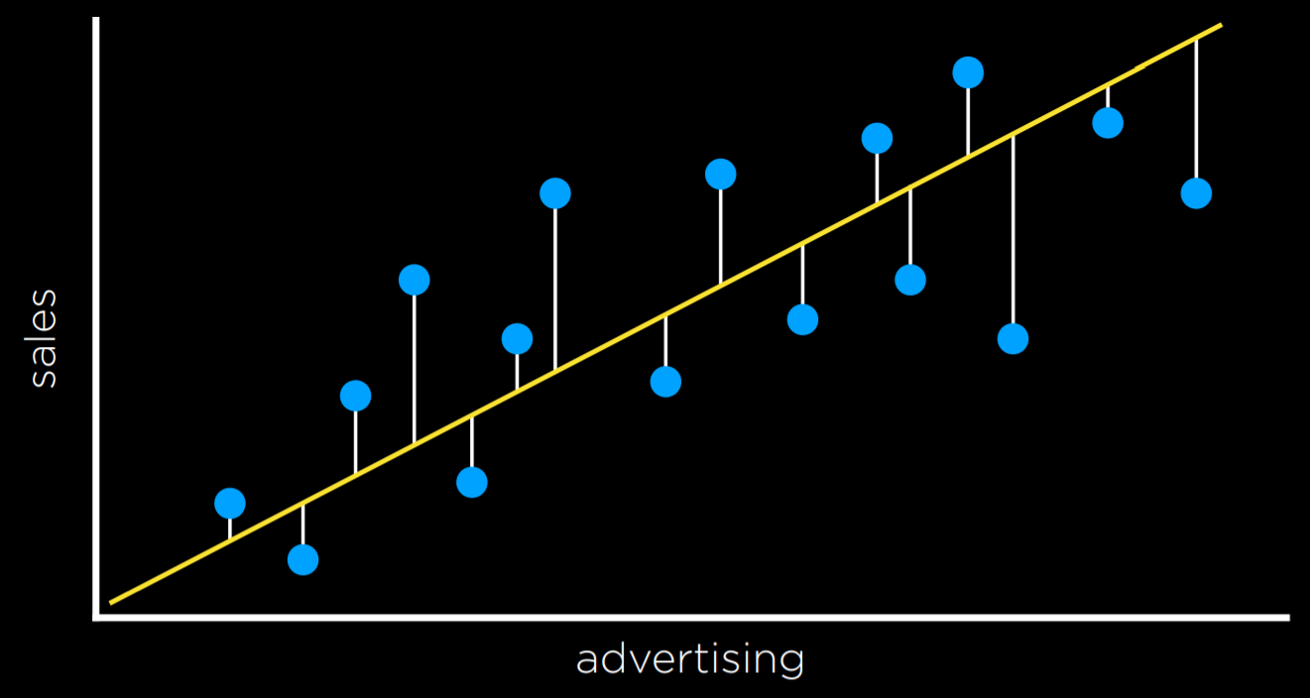
Можно выбрать функцию потерь, которая лучше всего служит его целям. L₂ наказывает выбросы более строго, чем L₁, потому что он выравнивает разницу. L₁ можно визуализировать путем суммирования расстояний от каждой наблюдаемой точки до прогнозируемой точки на линии регрессии:
Переобучение
Переобучение — это когда модель настолько хорошо соответствует обучающим данным, что плохо работает на других наборах данных. В этом смысле функции потерь — палка о двух концах. В двух примерах ниже функция потерь минимизируется так, что потери равны 0. Однако маловероятно, что это будет хорошо соответствовать новым данным.
Например, на левом графике точка рядом с красной в нижней части экрана, скорее всего, будет означать «Дождь» (синяя). Однако в случае с переобученной моделью она будет классифицироваться как «Без дождя» (красный).
Регуляризация
Регуляризация — это процесс наказания более сложных гипотез в пользу более простых и общих гипотез. Мы используем регуляризацию, чтобы избежать переобучения.
При регуляризации мы оцениваем стоимость функции гипотезы h путем сложения ее потерь и меры ее сложности.
cost(h)=loss(h) + \(\lambda\) complexity(h)
Лямбда (λ) — это константа, которую мы можем использовать, чтобы модулировать, насколько сильно наказывать за сложность нашей функции стоимости.
Один из способов проверить, не переучили ли мы модель, — это перекрестная проверка с отсрочкой. В этом методе мы разделяем все данные на две части: обучающий набор и тестовый набор. Мы запускаем алгоритм обучения на обучающем наборе, а затем смотрим, насколько хорошо он предсказывает данные в тестовом наборе. Идея здесь заключается в том, что, тестируя данные, которые не использовались в обучении, мы можем измерить, насколько хорошо обобщается обучение. Чем выше λ, тем дороже обходится сложность.
Недостатком перекрестной проверки с отсрочкой является то, что мы не можем обучить модель на половине данных, поскольку она используется для целей оценки. Способ справиться с этим — использовать перекрестную проверку k-Fold. В этом процессе мы делим данные на k наборов. Мы запускаем обучение k раз, каждый раз исключая один набор данных и используя его в качестве тестового набора. В итоге мы получаем k различных оценок нашей модели, которые мы можем усреднить и получить оценку того, как наша модель обобщает без потери каких-либо данных.
scikit-learn
Как это часто бывает в Python, существует множество библиотек, которые позволяют нам удобно использовать алгоритмы машинного обучения. Одна из таких библиотек — scikit-learn. Чтобы установить библиотеку выполните pip install scikit-learn.
В качестве примера мы собираемся использовать набор данных CSV о поддельных банкнотах.
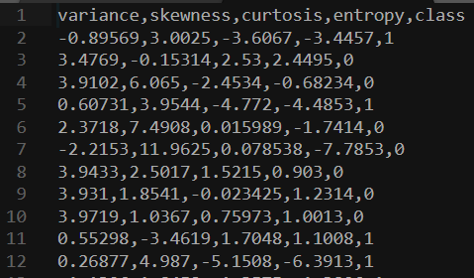
Четыре левых столбца — это данные, которые мы можем использовать, чтобы предсказать, является ли банкнота подлинной или поддельной. Это внешние данные, предоставленные человеком и закодированные как 0 и 1. Теперь мы можем обучить нашу модель на этом наборе данных и посмотреть, сможем ли мы предсказать, являются ли новые банкноты подлинными или нет.
import csv
import random
from sklearn import svm
from sklearn.linear_model import Perceptron
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
модель = Perceptron()
# модель = svm.SVC()
# модель = KNeighborsClassifier(n_neighbors=1)
# модель = GaussianNB()
Обратите внимание, что после импорта библиотек мы можем выбрать, какую модель использовать. Остальная часть кода останется прежней. SVC означает классификатор опорных векторов (который мы знаем как машину опорных векторов). KNeighborsClassifier использует стратегию k-соседей и требует в качестве входных данных количество соседей, которые он должен учитывать.
# Читаем данные из файла
with open("banknotes.csv") as f:
reader = csv.reader(f)
next(reader)
данные = []
for строка in reader:
данные.append({
"признаки": [float(ячейка) for ячейка in строка[:4]],
"метка": "Подлинная" if строка[4] == "0" else "Поддельная"
})
# Разделите данные на группы обучения и тестирования
отложить = int(0.40 * len(данные))
random.shuffle(данные)
тестирование = данные[:отложить]
обучение = данные[отложить:]
# Обучить модель на тренировочном наборе
X_обучение = [строка["признаки"] for строка in обучение]
y_обучение = [строка["метка"] for строка in обучение]
модель.fit(X_обучение, y_обучение)
# Делаем прогнозы на тестовом наборе
X_тестирование = [строка["признаки"] for строка in тестирование]
y_тестирование = [строка["метка"] for строка in тестирование]
предсказания = модель.predict(X_тестирование)
# Подсчитайте, насколько хорошо мы справились
верных = 0
неверных = 0
всего = 0
for настоящее, предсказанное in zip(y_тестирование, предсказания):
всего += 1
if настоящее == предсказанное:
верных += 1
else:
неверных += 1
# Распечатать результаты
print(f"Результат для модели {type(модель).__name__}")
print(f"Верных: {верных}")
print(f"Неверных: {неверных}")
print(f"Правильность: {100 * верных / всего:.2f}%")
Эту ручную версию запуска алгоритма можно найти в исходном коде этой лекции banknotes0.py. Поскольку алгоритм часто используется аналогичным образом, scikit-learn содержит дополнительные функции, которые делают код еще более кратким и простым в использовании, и эту версию можно найти в файле banknotes1.py.
Обучение с подкреплением
Обучение с подкреплением — это ещё один подход к машинному обучению, при котором после каждого действия агент получает обратную связь в виде вознаграждения или наказания (положительное или отрицательное числовое значение).
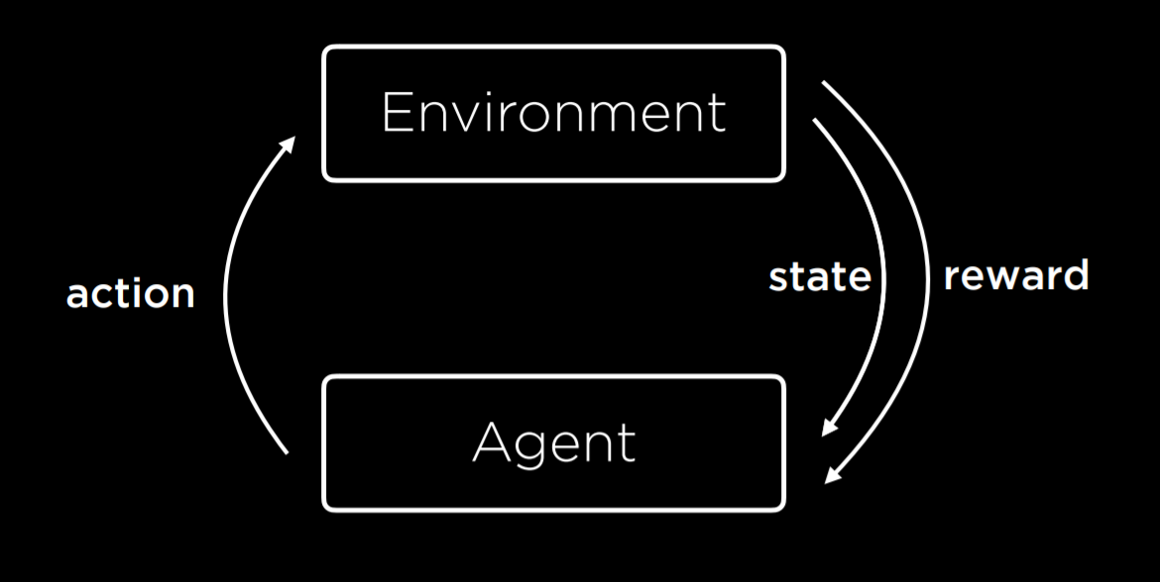
Процесс обучения начинается с того, что среда предоставляет агенту состояние. Затем агент выполняет действие над состоянием. На основании этого действия среда вернёт агенту состояние и награду, причём награда может быть положительной, делая поведение более вероятным в будущем, или отрицательной (т. е. наказанием), делая поведение менее вероятным в будущем.
Этот тип алгоритма можно использовать, например, для обучения шагающих роботов, где за каждый шаг возвращается положительное число (награда), а за каждое падение — отрицательное число (наказание).
Марковские процессы принятия решений
Обучение с подкреплением можно рассматривать как марковский процесс принятия решений, обладающий следующими свойствами:
- Набор состояний S
- Набор действий Действия(S)
- Модель перехода P(s’ | s, a)
- Функция вознаграждения R(s, a, s’)
Например, рассмотрим следующую задачу:
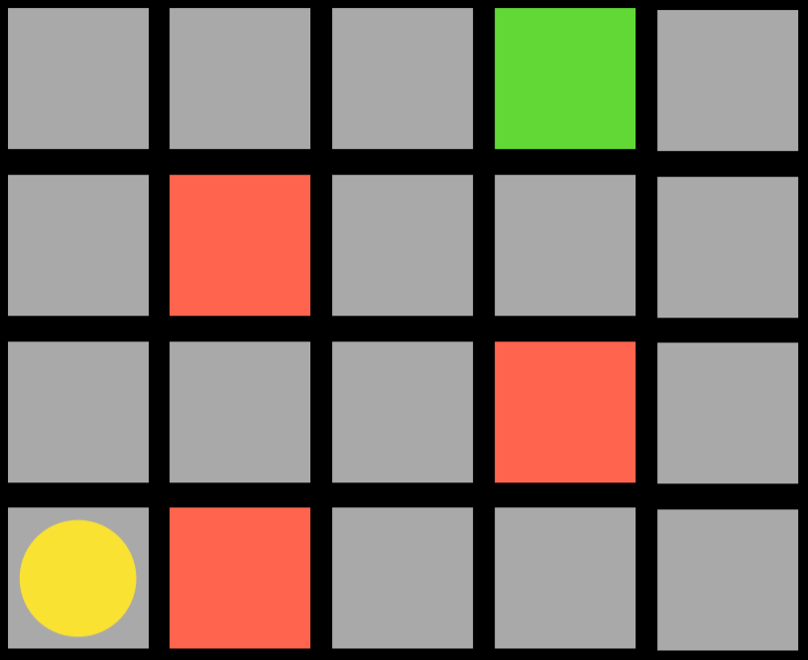
Агент — это жёлтый круг, и ему нужно добраться до зелёного квадрата, избегая красных квадратов. Каждый квадрат в задаче — это состояние. Движение вверх, вниз или в стороны — это действие. Модель перехода даёт нам новое состояние после выполнения действия, а функция вознаграждения определяет, какую обратную связь получает агент. Например, если агент решит пойти направо, он встанет на красный квадрат и получит отрицательный отзыв. Это означает, что агент узнает, что, находясь в нижнем левом квадрате, ему следует избегать движения направо. Таким образом, агент начнёт исследовать пространство, узнавая, каких пар состояние-действие ему следует избегать. Алгоритм может быть вероятностным, выбирая различные действия в разных состояниях на основе некоторой вероятности, которая увеличивается или уменьшается в зависимости от вознаграждения. Когда агент достигнет зелёного квадрата, он получит положительную награду, узнав, что выполнить действие, которое он совершил в предыдущем состоянии, выгодно.
Q-обучение
Q-Learning — это одна из моделей обучения с подкреплением, где функция Q(s, a) выводит оценку ценности выполнения действия a в состоянии s.
Модель начинается со всех оценочных значений, равных 0 (Q(s,a) = 0 для всех s, a). Когда действие выполнено и получено вознаграждение, функция делает две вещи: 1) оценивает значение Q(s, a) на основе текущего вознаграждения и ожидаемых будущих вознаграждений и 2) обновляет Q(s, a) приняв во внимание как старую оценку, так и новую оценку. Это даёт нам алгоритм, который способен улучшить свои прошлые знания, не начиная с нуля.
Q(s, a) ⟵ Q(s, a) + α(new value estimate - Q(s, a))
Обновлённое значение Q(s, a) равно предыдущему значению Q(s, a) с добавлением некоторого обновляющего значения. Это значение определяется как разница между новым значением и старым значением, умноженная на α, коэффициент обучения. Когда α = 1, новая оценка просто перезаписывает старую. Когда α = 0, оценочное значение никогда не обновляется. Повышая и понижая α, мы можем определить, насколько быстро предыдущие знания обновляются новыми оценками.
Новая оценка стоимости может быть выражена как сумма вознаграждения (r) и оценки будущего вознаграждения. Чтобы получить оценку будущего вознаграждения, мы рассматриваем новое состояние, которое мы получили после совершения последнего действия, и добавляем оценку действия в этом новом состоянии, которое приведёт к наибольшему вознаграждению. Таким образом, мы оцениваем полезность совершения действия a в состоянии s не только по полученной награде, но и по ожидаемой полезности следующего шага. Значение оценки будущего вознаграждения иногда может отображаться с гаммой коэффициентов, которая определяет, сколько будут оцениваться будущие вознаграждения. В итоге мы получили следующее уравнение:
$$ Q(s,a) \leftarrow Q(s, a) + \alpha ((r+\gamma max_{a'}Q(s',a'))-Q(s,a)) $$Жадный алгоритм принятия решений полностью игнорирует будущие предполагаемые вознаграждения, вместо этого всегда выбирая действие a в текущем состоянии s, которое имеет наивысшее Q(s, a).
Это подводит нас к обсуждению компромисса между исследованием и эксплуатацией. Жадный алгоритм всегда эксплуатирует, предпринимая уже установленные действия, чтобы привести к хорошим результатам. Однако он всегда будет следовать одним и тем же путём к решению, никогда не находя лучшего пути. Исследование, с другой стороны, означает, что алгоритм может использовать ранее неисследованный маршрут на пути к цели, что позволяет ему находить более эффективные решения на этом пути. Например, если вы слушаете одни и те же песни каждый раз, вы знаете, что они вам понравятся, но вы никогда не узнаете новые песни, которые могут вам понравиться ещё больше!
Для реализации концепции разведки и эксплуатации мы можем использовать жадный алгоритм ε (эпсилон). В этом типе алгоритма мы устанавливаем ε равным тому, как часто мы хотим двигаться случайным образом. С вероятностью 1-ε алгоритм выбирает лучший ход (эксплуатацию). С вероятностью ε алгоритм выбирает случайный ход (исследование).
Ещё один способ обучения модели обучения с подкреплением — давать обратную связь не по каждому шагу, а по окончании всего процесса. Например, рассмотрим игру Ним. В этой игре по стопкам распределено разное количество предметов. Каждый игрок берет любое количество предметов из любой одной стопки, и игрок, который возьмёт последний предмет, проигрывает. В такой игре необученный ИИ будет играть случайным образом, и победить его будет легко. Чтобы обучить ИИ, он начне т случайную игру и в конце получит награду 1 за победу и -1 за поражение. Например, когда он тренируется в 10 000 играх, он уже достаточно умен, чтобы его было трудно победить.
Обучение без учителя
Во всех случаях, которые мы видели раньше, например, в контролируемом обучении, у нас были данные с метками, на которых алгоритм мог учиться. Например, когда мы обучали алгоритм распознаванию фальшивых банкнот, каждая банкнота имела четыре переменных с разными значениями (входные данные) и тем, фальшивая она или нет (этикетка). При обучении без учителя присутствуют только входные данные, и ИИ изучает закономерности в этих данных.
Кластеризация
Кластеризация — это задача обучения без присмотра, которая берет входные данные и организует их в группы таким образом, что похожие объекты оказываются в одной группе. Это можно использовать, например, в генетических исследованиях, когда пытаются найти похожие гены, или при сегментации изображений, когда определяют разные части изображения на основе сходства между пикселями.
k-центров кластеризация
Кластеризация k-центров — это алгоритм выполнения задачи кластеризации. Он отображает все точки данных в пространстве, а затем случайным образом размещает в пространстве k центров кластеров (сколько их должно решать программисту; это начальное состояние, которое мы видим слева). Каждый центр кластера — это просто точка в пространстве. Затем каждому кластеру присваиваются все точки, которые находятся ближе всего к его центру, чем к любому другому центру (это средний рисунок). Затем в итеративном процессе центр кластера перемещается в середину всех этих точек (состояние справа), а затем точки снова переназначаются на те кластеры, центры которых теперь к ним ближе всего. Когда после повторения процесса каждая точка остаётся в том же кластере, что и раньше, мы достигли равновесия и алгоритм завершается, оставляя точки, разделённые между кластерами.
